AI Memory: Technical Foundations
A comprehensive review (part 2/4)
See [Part 1] for the history of how memory evolved to its current form. Or see the full report here.
If you are building AI Memory, reach out to Jean: jonathan@jeanmemory.com
Introduction
To recap Part 1, modern AI is no longer just a Large Language Model (LLM). We are now dealing with an entire “context engineering stack,” in which AI Memory is a core component. AI applications and agents breathe context as oxygen. Memory is how we provide the right context at the right time to improve system performance.
We overviewed the humble beginnings of memory from basic RAG. Here, we will explore how this has evolved into today’s bleeding edge of intelligent, agentic memory. We explore advanced memory architectures and offer helpful design principles for building your memory systems.
This section will aim to be objective, but we do include helpful notes for developers that we have picked up from building many different memory products. We will also aim to drive home two opinionated takes:
-
RAG is a transitional technology. RAG was retrofitted for memory but will eventually be replaced by hybrid and agentic solutions. Current evals are broken and should be re-evaluated entirely. We stress that what is truly important for performance is recalling the “right context at the right time.”
-
Fragmentation of Solutions: There’s no “one size fits all” solution. We will continue to see different products emerging built for different use cases and tasks.
Section 1: What is Memory?
1.1 Defining the Concept
Before exploring memory in greater depth, we should properly define it and establish a conceptual foundation. While companies like IBM have defined memory differently in the past, we introduce a new definition that captures all that memory is and can be [IBM].
“AI Memory refers to how AI systems encode, organize, and recall information from experience to improve task performance.”
If we consider human memory, we see that the brain not only acts as simple storage and retrieval. The human mind filters, encodes, forgets, and constantly reorganizes itself.
-
This functionally defines memory as a means to improve system and task performance.
-
This definition does not limit memory to simple storage and retrieval but marks memory as an intelligent process of its own capable of deriving and triangulating new information.
-
This definition purposefully restricts memory to information that has been experienced by the system, otherwise we would include the internet as memory. Memory is read/write.
Not all memories are created equal. We will explore different forms of memory and types of context that we are encoding.
Short-Term and Long-Term Memory
As humans navigate the world, we are constantly flooded with information, such as the name of your waitress at IHOP or the date of your anniversary.
We remember information based on perceived future importance, and memories are pruned when they’re deemed unuseful. Information may be forgotten immediately, enter our short-term memory before being discarded, or become stored in long-term memory. While the future utility of your waitress’ name may not hold much weight, forgetting your anniversary may have severe consequences.
The same is true for AI Memory systems. Most information that we experience is transient noise, but we should build systems that are capable of storing signals that will be of future importance.
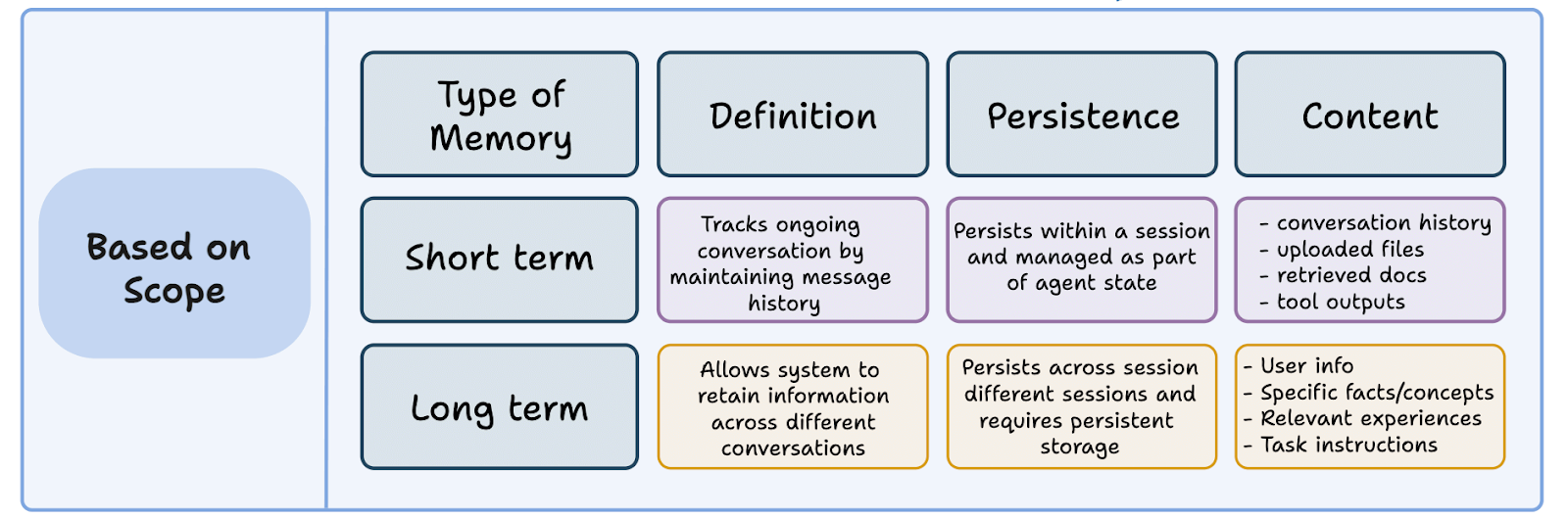
Short-Term Memory
Generally, short-term memory is considered to be anything that has occurred in the chat or session, such as recent messages or tool calls that may be important to maintain continuity.
By appending recent context to new prompts, session history is maintained. The largest issue with short-term memory is context rot, in which a conversation lengthening means diluting an agent’s attention span, often past 32k tokens.
There are emerging methods to improve short-term memory. Even as context windows expand past 1 million tokens, solutions that improve short-term memory include sliding context windows and storing older information in a separate retrievable cache, summarizing and compacting conversations, and maintaining a separate “scratch pad.”
Even as context windows expand, there will always be performance improvements to be found in improving short-term memory through these methods. In the words of Anthropic:
“Waiting for larger context windows might seem like an obvious tactic. But it’s likely that for the foreseeable future, context windows of all sizes will be subject to context pollution and information relevance concerns—at least for situations where the strongest agent performance is desired. To enable agents to work effectively across extended time horizons, we’ve developed a few techniques that address these context pollution constraints directly: compaction, structured note-taking, and multi-agent architectures.”
-Anthropic, Context Engineering
Long-Term Memory
While the goal of short-term memory is to improve session continuity, long-term memory is the persistent, externalized knowledge store that allows an AI to learn, personalize, and build understanding across sessions over days, months, and even years. This is the core focus of modern AI Memory systems and this overview.
For example, recent implementations of ChatGPT enable your AI to remember your preferences over time as well as across chat sessions. Customer service calls have historically started each session with a fresh slate but AI voice agents have the potential to remember who you are, your customer information, previous issues, and any other salient information relevant to serving you better.
Types of Memories
Rather than throw all memories into a giant pile and hope that we can build systems that make sense of the chaos, we can add some organization using principles based on human psychology. Generally the industry categories for memories are considered semantic (factual), episodic (temporal), procedural (process), and associative (linking across memories).
While categories provide useful intuitions, memories are complex and cannot often be contained by such simple organization. A single memory may contain episodic context, semantic facts, and procedural knowledge simultaneously. Too much categorization makes memory brittle. Meanwhile, too little structure hurts performance.
This behavior mirrors the difficulties that Anthropic also calls out in engineering agentic systems. This tradeoff between brittle, complex structure and vague, high-level guidance is often the most important design consideration in engineering AI and Memory systems that we will explore in more detail in the technical principles section.
“At one extreme, we see engineers hardcoding complex, brittle logic in their prompts to elicit exact agentic behavior. This approach creates fragility and increases maintenance complexity over time. At the other extreme, engineers sometimes provide vague, high-level guidance that fails to give the LLM concrete signals for desired outputs or falsely assumes shared context.”
-Anthropic, Context Engineering
You’ll notice that each memory type has different challenges. If you know what memory type will predominate your application, consider optimizing for it. Lack of foresight here can leave you months into building a complex architecture before realizing a much simpler architecture would have sufficed.
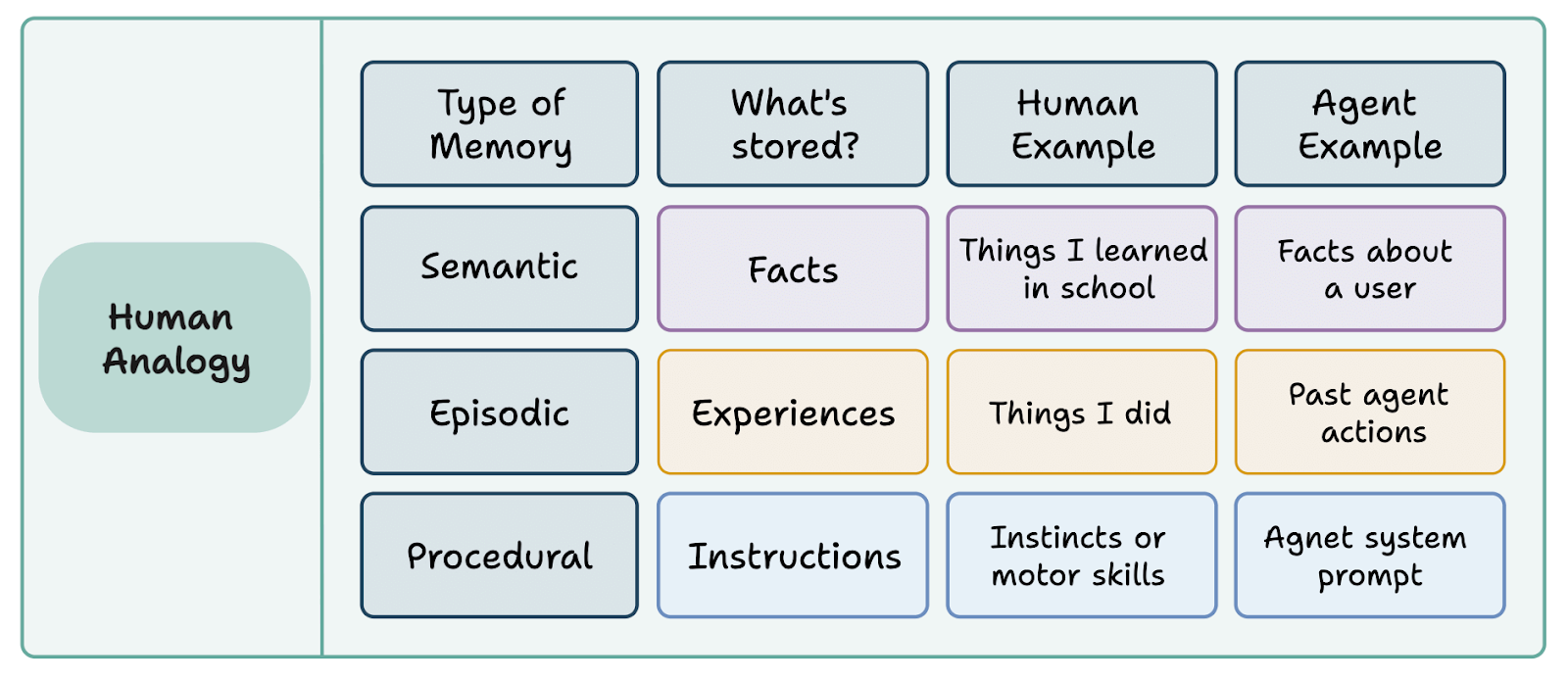
Semantic Memory: Factual Knowledge
Semantic memory stores facts and general knowledge that are true independent of when or how it was learned. This includes user preferences (”prefers dark mode”), professional details (”works as a product manager at TechCorp”), and domain knowledge (”Paris is the capital of France”). The key characteristic is that these facts exist outside any specific temporal context.
Common challenge: facts can become outdated as users change jobs, relocate, or update preferences, requiring systems to handle versioning and updates.
Episodic Memory: Specific Events and Experiences
Episodic memory captures particular interactions and events with their temporal and contextual details. Unlike semantic memory’s timeless facts, episodic memories are inherently tied to when and where they occurred (”our conversation last Tuesday where we discussed the API refactor”) or “you mentioned feeling stressed about the presentation last week.” This memory type enables conversational continuity and case-based reasoning, allowing AI systems to reference past interactions naturally and learn from specific experiences.
Common challenge: often, we stamp memories with a date and time. But when do you update them if they repeat? What if you learn about a date of birth? What date do you use? What about general time ranges such as the 1970s?
Procedural Memory: How to Do Things
Procedural memory encodes processes, workflows, and learned behaviors. This includes operational procedures, such as communication protocols taken when a patient enters the ER, and personal workflows, such as starting every working session with a summary of your inbox.
Often learned through repeated experience or reinforcement learning, procedural memory allows agents to perform complex sequences efficiently without re-reasoning through each step.
Common challenge: procedural knowledge tends to drift and fork. The real process often lives partly in documents, partly in tools, and partly in undocumented team habits. This makes it hard to keep one canonical version up to date, detect when behavior diverges from the procedure, or safely evolve workflows over time. Encoding procedures too rigidly makes agents brittle; encoding them too loosely means they silently revert to ad-hoc behavior.
Associative Memory: Connections Between Memories
We are proposing a new category of memories that exist from forming connections between existing memories. Associative memory represents the web of relationships between different pieces of stored information. For instance, knowing that a user is working under Professor X and a separate memory that Professor X works at the Computer Science Department at Stanford may create a novel connection that the user is affiliated with Stanford. Often, associative memory excels when creating abstract understanding on top of individual memory data points. Such as a user who is constantly trying new things being categorized as high in personality openness and novelty-seeking.
Common challenge: computers perform poorly at making proper connections between memories. Graph relational databases have proven to be too rigid when scope is broad. The nature of forming new memories is also unstable and may introduce false memories. This is why naive graph DBs struggle.
1.2 Types of Context
Memories can often be thought of as simple storage of context. When designing systems that should retain information from their experiences, we should consider that different systems are designed to navigate different environments and contexts.
By Modality:
Yoshua Bengio, AI researcher, recently stated that we likely shouldn’t call modern AI LLMs anymore since they are really multi-modal and not language based. While they started as language-based, they can now take inputs of images, for example. [The Minds of Modern AI] In other words, memories are not necessarily just textual. They can be images, videos, or other types entirely.
Structure and Precision
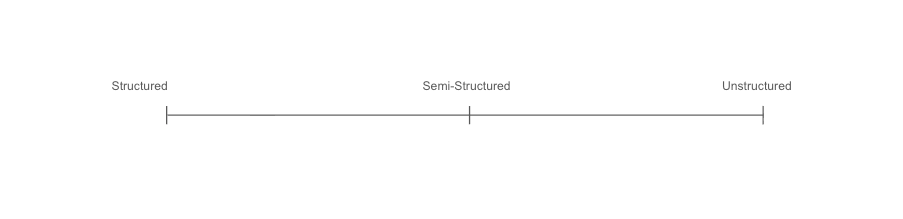
Note that there is a tradeoff between structure and unstructured context. We will also save much of this discussion for the section on technical design principles.
Some memories require strict rules in how they are saved and recalled. When dealing with legal documents or financial matters, we often need to be exact and can not afford to lose precision in understanding. Many professionals build automations that reuse templates that are core to a firm’s value proposition and intellectual property. For tasks that require this precision, we must build strict systems. We may prompt systems to format and verify text exactly as it is stored and to interact with the memory system using JSON formatting.
On the other hand, when creating a memory system that recalls previous zoom conversations, we may at first design the system with the ability to quickly review summaries of various conversations. “What did I talk about with Josh Brener last week?” Too much structure may unnecessarily hinder performance.
Source and Propriety
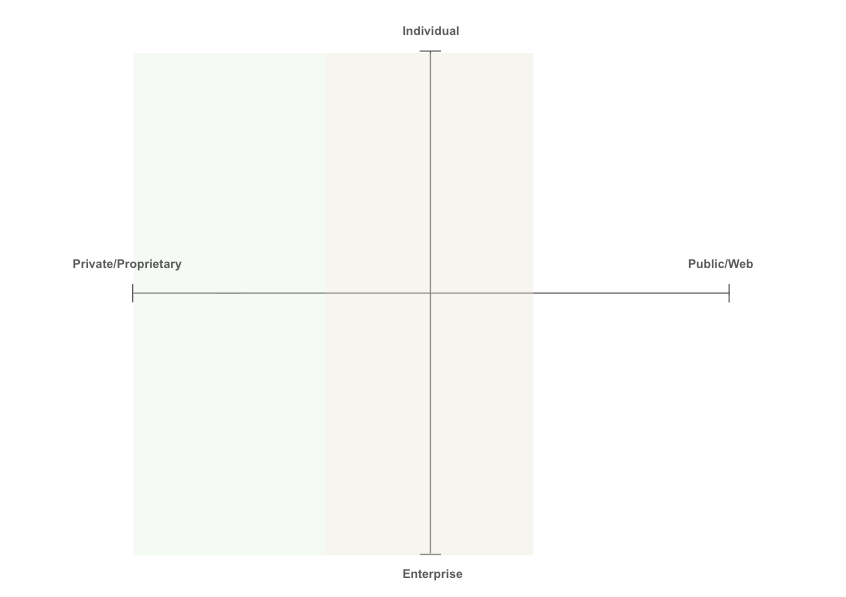
Context may be categorized across axes of propriety (private or public on the web) and what entity it relates to, whether an individual or enterprise.
-
Individual memory is often heavily semantic, unstructured, and related to factual data and preferences about the individual or user.
-
Enterprise information is often procedural, structured, and related to workflows, Slack, internal data, etc. Enterprise memory is often heavily dependent on integrating with internal applications where value can be unlocked by connecting context across siloed data stores.
There is a significant amount of context residing on the web and accessible by tooling such as web browsers. This context is largely commodified and not very valuable. However, we can still build agentic systems that navigate the web and use a memory store to complete tasks. The reason why we have purposefully restricted the definition of memory to information that is experienced by the AI is that there are separate tools more suited for dealing with this commodified information (including basic web search).
The line between context related to an enterprise or individual is often blurry. Each individual has a “severance effect” where context related to work is separate from the rest of their daily context. Even within each category, we often segregate context further between individual projects.
Work Self: This context is professional and task-oriented. It includes your projects, code, meetings, professional relationships, and team dynamics.
Life Self: This context is personal and private. It includes your preferences, habits, personal history, family relationships, and private thoughts or goals.
As we move further to the left in the green shaded area, where individual and enterprise data becomes more proprietary, context becomes more valuable. As you can imagine, sensitive individual and enterprise data leads to privacy considerations and consumer protections.
It took years for many companies to scaffold secure LLMs running in the enterprise due to risk of leaking proprietary information. We should anticipate similar precautions with memory systems.
1.3 High-Level Memory Process
To provide a general outline, we can break memory into distinct processes. Pragmatically, we will write this section through the lens of modern agentic systems, with a simple depiction below.
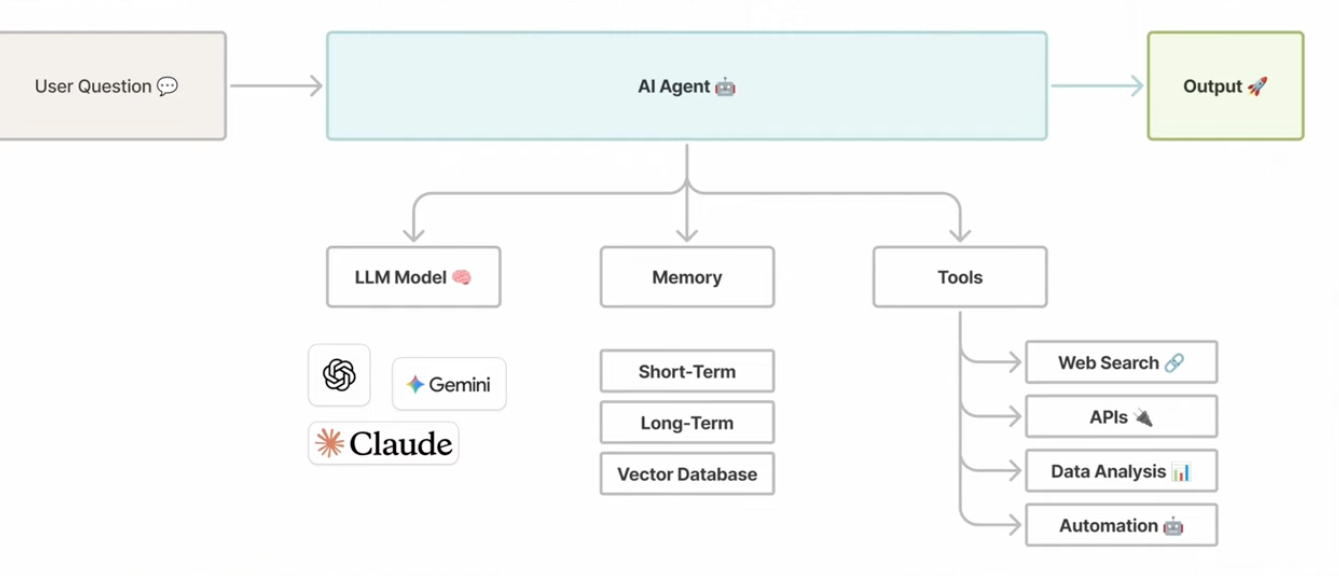
Before we jump into each individual process, we first need to decide “how” and “when” a memory is passed along. There are fundamentally two decision pathways here.
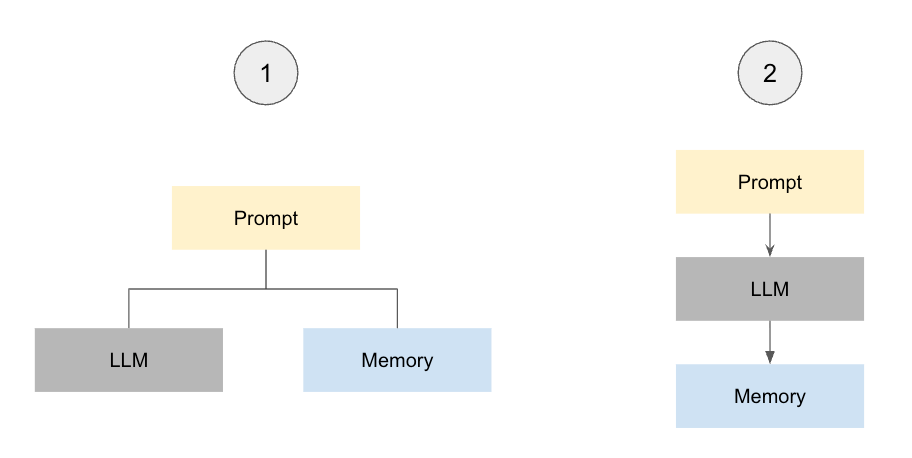
Pathway 1 runs parallel, where we pass along the full prompt to the LLM and memory system in tandem. We can make our AI system faster and “non-blocking” by designating this as a separate background process that does not interfere with LLM inference. In many cases, memory systems must validate if there are conflicting memories to reconcile. This process may take time and will create a bottleneck that we prevent by keeping processes independent.
We can pass along every message in full or process memories before sending them to memory. Processing can be agentic/intelligent or programmatic/rule based to decide what is sent. For instance, if we always want to remember when customers send messages with item numbers, we can program this directly.
Pathway 2 is unified, where the memory system itself presents as a tool to be autonomously called by the LLM, often through the model context protocol. An example of this is coding on Cursor. A coding agent may enter a loop to fix a bug. After a major milestone has been reached, the milestone may be deemed meaningful to save down as a progress report and the coding agent will call memory directly.
This method is especially useful when the context of the entire chat or session is required for deciding what to save and when.
Memory is a 3-Part Process
To understand where current systems fail, we must move beyond the idea of memory as a static storage system. Memory in AI is a computational pipeline designed to recall “right context, right time.”
On this point, many memory products now advertise scores on retrieval benchmarks like LoCoMo. LoCoMo is a question-answering benchmark over long, synthetic conversations: it measures whether an agent can pull the right fact from a transcript, not whether it has “good memory.” Letta’s work shows that a simple filesystem-based setup reaches 74% accuracy with GPT-4o mini, outperforming specialized “memory” stacks. [Benchmarking] Zep also accused Mem0 of similar benchmark hacking and poor testing. As we move into context-heavy, task-specific agents, LoCoMo is best treated as a useful smoke test, not a sufficient eval; systems should be judged on end-to-end task performance for the actual use case.
We can break this pipeline down into three relatively independent downstream phases:
-
Experience (E)
-
Storage (S)
-
Recall (R)
Ultimately, the quality of recall for a defined task is what makes an effective memory system. This is an important point, because recall must also be designed with the agent’s unique Task (T) in mind. There are no perfect evals other than your unique case.
Here is an overview of what these abstract processes look like in a programmatic flow.

Phase 1: Experience (Input Layer)
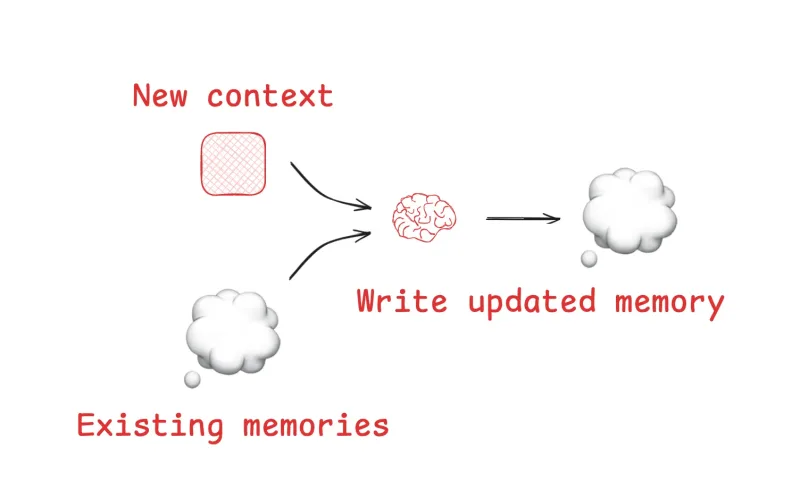
Experience is the point of contact between the data stream and external memory. This is where the system decides what is worth remembering. In 90% of current industry implementations, this step is passive and the system simply passes along every interaction. This is often a mistake.
Effective memory systems distinguish between signal and noise at the point of entry. Remember, we want to create systems that distinguish what will be useful in the future. We use memory in the first place to fight against context pollution. We do not want to also pollute our memory store.
High-performance memory is non-blocking. While novice systems force the agent to pause and save data, efficient architectures run as an asynchronous background process that distills insight without introducing latency. We can avoid this bottleneck by running a secondary background process that scans the interaction for valuable signals, de-duplicates repeated information, discards conversational filler, and extracts core facts or intent before they ever reach storage.
Phase 2: Storage (The Organization Layer)
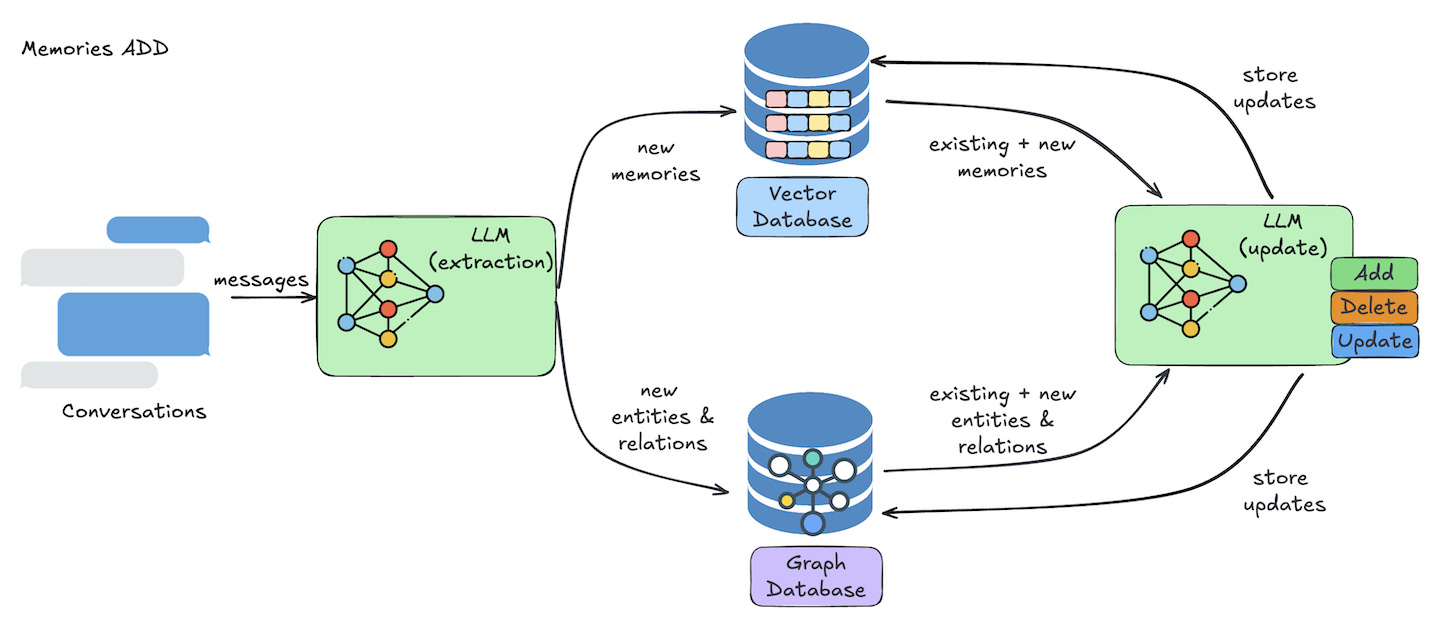
Once information passes the gate, it must be organized. In our everyday lives, we expect our clothes to be in our closet. When they are in the pantry, it confuses us and leaves us stuck. The same goes for memory systems. We must organize memories for future utility.
If we store a user’s preference for “Python” under a generic “Notes” tag, it may be lost. If we organize it under “Coding Preferences” or link it to “Backend Projects,” the likelihood of successful retrieval increases. Once again, we find ourselves balancing rigid structure and vague guidance. If we create too many directories, an AI will begin to get confused when determining which to read and write from. If the organization is too unclear or complex for a human, we shouldn’t expect an AI to perform better.
This layer is responsible for the architecture of storage. It answers questions like:
-
Does this new information contradict old information?
-
Is this a standalone fact, or does it modify an existing memory?
-
What entities or other memories might have relationships with this memory?
-
Should we log this as a precise fact, a summarized memory, or link it to an artifact?
We will explore the specific technical architectures (Vectors, Graphs, etc.) that achieve this in the next section, but the high-level goal remains constant: building memory that recalls “right context, right time.”
Sleep-Time Compute
Sleep-Time Compute is a term coined by Letta. [STC] The human mind reorganizes our memory while we sleep. Well-designed memory does the same. We are not only storing. We must also edit, reorganize, compact, prune, distill, etc. to make sure that our storage (S) is always organized and optimized for recall (R). If we expect there to be some upper limit for the amount of memories that a system can reasonably maintain, we must design our systems to balance the adding of new memories with freeing space for new memories.
Phase 3: Recall (Retrieval Layer)
If storage is making sure everything is ready and findable, recall is the process of querying and retrieving this data. It is where the system pulls the information that is useful for answering the task at hand.
While most modern memory systems do nothing more than simple retrieval, we make the argument in this paper that creative synthesis and reasoning on top of memory data points will be critical in the design of next-generation memory products.
Our rationale is that if the goal of memory systems is to optimize Recall (R) for Task (T), and we can achieve more accurate recall by reasoning over memory data points, we should.
Levels of Recall Depth:
-
Static Context Injection (list_memory): The system blindly dumps the last N messages or pinned notes into the prompt. Fast, but zero intelligence.
-
Semantic / Graph Retrieval (search_memory): The system takes the user’s query (”Help me fix this bug”) and searches the database or prior messages for mathematically similar concepts to the message or relevant words such as “bug”.
-
Intelligent Query Generation (deep_memory): The system pauses to ask: “What do I need to know to answer this?” Then locates and packages important information for the agent.
-
Includes iterative retrieval: Sometimes the first retrieval reveals that we are asking the wrong question. An agentic memory system allows for multi-hop retrieval: fetching A, realizing A requires B, and then fetching B.
-
Example: If the user asks “Why is my deployment failing?”, a naive system searches for “deployment failing.” An intelligent system generates new queries: “What is the user’s tech stack?”, “What were the last 3 error logs?”, and “Check recent changes to config files.”
-
There is no reason that we can not build multi-layer, long-context, coordinating agentic memory that we coin “deep memory.” It is just often prohibitively slow or expensive.
-
To summarize, the ultimate measure of a memory system is not how much it remembers, but how well it uses stored information from experience to improve performance of the agent’s task. We should design our memory pipeline to optimize Recall (R) for the defined Task (T).
Section 2: Technical Architecture
2.1 Overview:
The technical foundation of memory and its pipeline is set. But different uses of memory require different architectures for their specific use cases. Some may prioritize latency and semantic precision while others prioritize intelligence, quality of recall, and the maintenance of relationships across memories.
2.2 Technical Design Principles
Before we choose between specific tools (like Vector vs. Graph), we must understand the constraints that lead to our decisions between them.
To evaluate these architectures objectively, we have synthesized a unified theory based on Politzki’s Law, The Memory Frontier, and The Routing Constraint.
These formalize the chain of logic behind every memory decision:
-
AI’s Limitation: AI struggles with complex problems. We need relevant information to help our AI navigate problems and tasks (Politzki’s Law).
-
The Constraint: Recalling context through inference is expensive at scale, so we must partition it (The Memory Frontier).
-
The Optimization: To find data within these partitions, we need a clean organizational ontology (The Routing Constraint).
1. AI’s Limitation: Politzki’s Law of Complexity
While humans are able to find solutions to complex problems with limited information, AI cannot generalize at the same level. We define this relationship as [Politzki’s Law].
Simply put, we can’t easily improve the intelligence of the LLMs we use, so the only variable we can reasonably improve is the context provided to the system. Memory is an important tool to do so.
-
The Premise: Modern AI lacks Generalization (G), the ability to reason with limited and disparate information, relative to humans.
-
The Problem: When Complexity (C) of problem space is high and Data (D) is low, AI fails because it cannot generalize (G) a solution like a human can.
-
The Solution (Memory): Since we cannot readily increase a model’s generalization (G), we are forced to use Memory to provide useful information (D) by injecting relevant context with the aim of maximizing performance of task (T) by effectively guiding the model towards appropriate vector programs.
2. The Constraint: The Memory Frontier
In order to retrieve the correct Data (D), we need to build an effective recall system. Most engineers frame memory as a database selection problem (”Vector vs. Graph”), but this is not the correct framing and perhaps the most dangerous misconception in today’s discussion on AI Memory systems. In an ideal world, we would recall only via inference.
For example, imagine a scratchpad containing every event on your calendar. The most elegant solution is to feed this entire context into an LLM and ask, “What time is lunch today?” This guarantees 100% recall because the model “sees” everything simultaneously and picks it out efficiently.
While we aspire to throw everything in the context window, the cost of attention scales quadratically O(_N_2) as the number of tokens (N) expands. This results in:
-
Increased latency.
-
“Lost in the middle” phenomena (forgetting).
-
Prohibitive cost.
To mitigate this, we commit the “original sin” of memory: we segment context to lower search space.
We start partitioning by introducing structure via directories, embeddings, and graphs. By dividing N tokens into P partitions, we eliminate the quadratic scaling cost of context. However, this introduces the problem of fragmentation.
Fragmenting context severs connections between context. For instance, if you have a memory that you have lunch today at 1 PM, but you have another work-related memory from a different partition that a client requested you reschedule and you agreed, the two cannot be reconciled.
The Efficient Frontier
Therefore, memory architecture is not just about choosing a database. A database and framework is only as helpful as how well it balances Partitioning and Recall (R) quality along the memory frontier:
Fast Memory (High Partitioning)
-
Tech: SQL, Key-Value, Vector RAG.
-
Physics: Splits context into thousands of tiny shards.
-
Pros: Linear scaling, instant retrieval, low cost.
-
Cons: High Fragmentation Risk. Logical connections between shards are severed. If vector similarity fails, the context is lost.
Slow Memory (Low Partitioning)
-
Tech: Agentic Reasoning, Long-Context Inference.
-
Physics: Maintains large, contiguous blocks of context.
-
Pros: High Synthesis. Can connect disparate facts (e.g., Clause A + Clause B) because they are processed together in inference.
-
Cons: Expensive and slow.
We should aim to find the Minimum Viable Partitioning, which segments data enough to enable fast recall, but keeps partitions large enough to preserve logical connections.
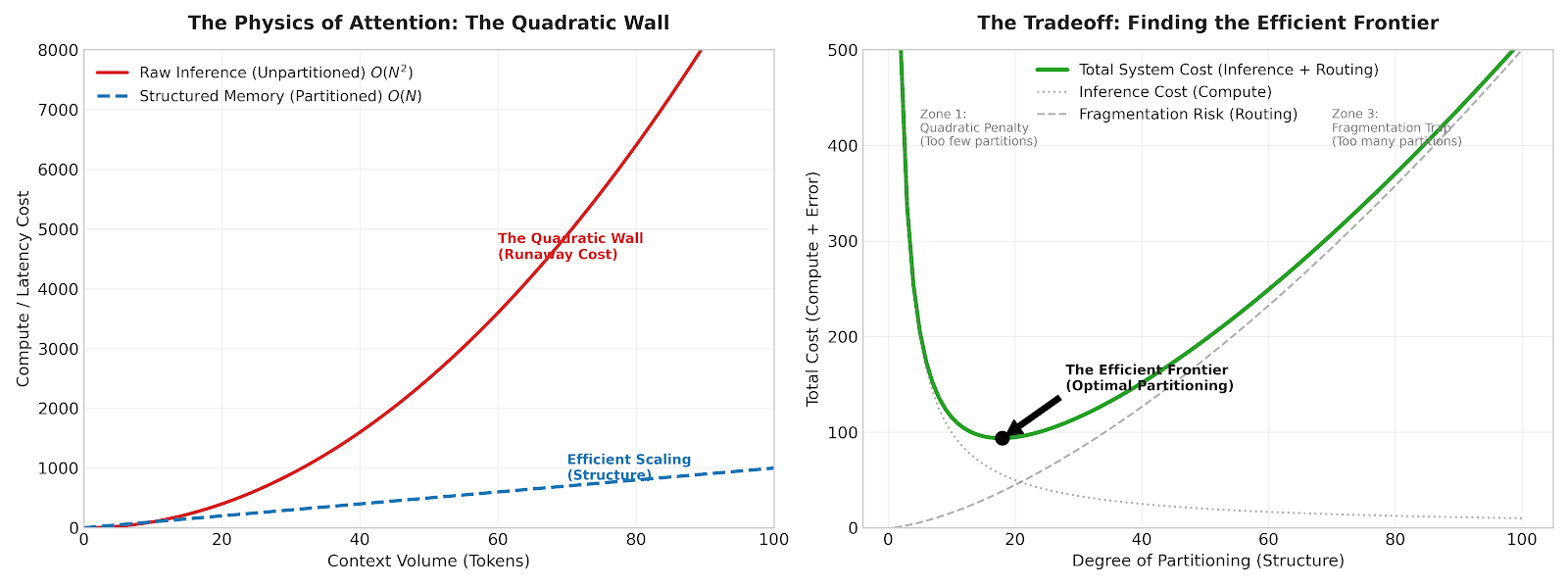
3. The Optimization: The Routing Constraint
The above principle tells us that there is a tradeoff between computational cost and the quantity of partitions. We also need to consider how we organize our memories amongst our partitions.
For example, we may find optimal partitioning=10. However, how do you distribute context across them? We should design the directories so that they each contain approximately the same quantity of tokens N. This distributes the search load across each partition and improves the quality of Recall (R).
We define this as The Routing Constraint:
“Partitioning effectively lowers search space but introduces fragmentation. To minimize the cost of fragmentation, we must apply efficient organization and ontologies to maintain logical connections across context.”
This segmentation is often more of an observational art than a science. A user’s memories may fall under “work,” “personal preferences,” “family,” “recent context,” so we should design the system with these partitions. However, for very general products, this is not always straightforward as different users use the product in drastically different ways. Giving the agent the leniency to self-organize through dynamic partitioning is an active area of research for us.
Example and Summary
Imagine a debugging agent trying to diagnose a production outage. By Politzki’s Law, the model alone cannot generalize a fix from a vague error message (“502s on checkout”) without more Data (D): it needs logs, recent deployments, runbooks, and incident history. The Memory Frontier forces us to partition that context so that it can realistically process context. The Routing Constraint then tells us we need these organized into logical categories: logs in one store, PRs in another, and runbooks in a third.
To summarize, AI relies on relevant context. We can use memory to make sure that it is recalling the right context at the right time. However, as context size N increases, we need to partition P the memory set to ensure that the cost of operations are not prohibitively expensive. To optimize this further, we need to organize context so that it’s distributed across categories in a way that balances the search load evenly.
2.3 Technical Architectures
As we see above, technical architectures are a means to an end. For low-context tasks, a simple file paired with inference suffices. But as memories grow and become more complex, architecture matters.
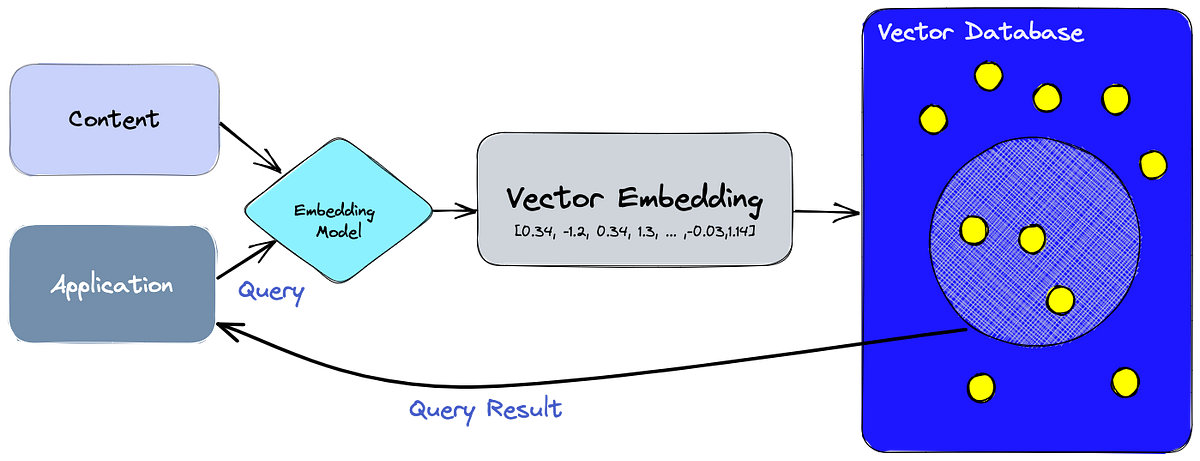
Vector/Embedding-Based Systems (RAG)
In part 1, we explored the history of memory. Retrieval Augmented Generation (RAG) was the first solution to be retrofitted to be used as memory. Notably, this development came before the introduction of MCP and effective structured output. We believe this led us down a path dependency that should be reconsidered. [RAG is not Memory] RAG was the obvious initial solution for memory. It is excellent for retrieving facts, but terrible for deriving understanding.
Today, RAG remains the most popular architecture. Vector databases work by converting text chunks into mathematical vectors (lists of numbers) and plotting them in multi-dimensional space. When a user asks a question, the system finds the “nearest neighbors,” the chunks of text that are mathematically most similar to the query. See below that “wolf,” “cat,” and “dog” all live near each other and are ranked similarly when searching for “kitten.”
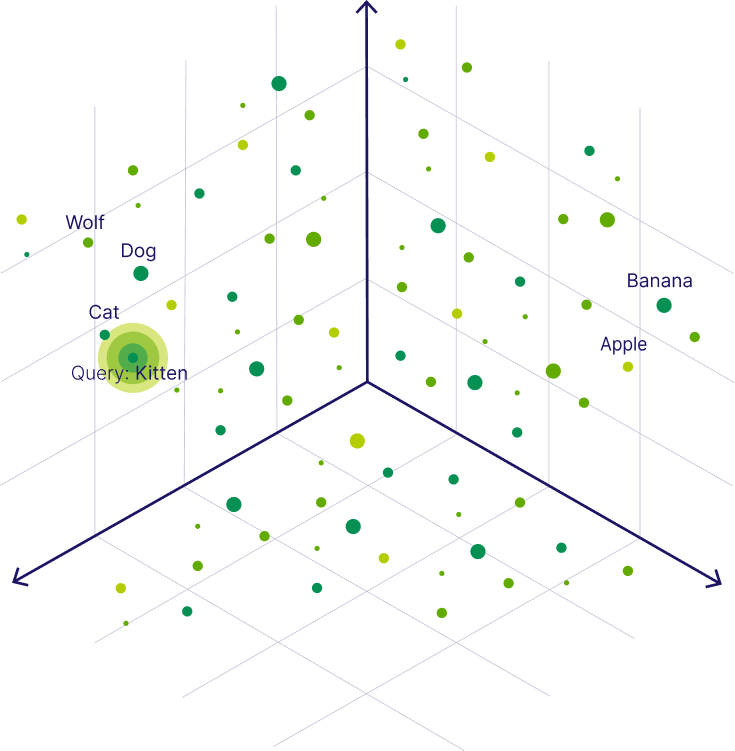
Vector databases maximize partitioning while maintaining a clean, fast search for closely related data points. However, saving memories in embedding space is far from perfect. Embedding models mostly capture semantic meaning and much is lost in translation when converted to embeddings, especially with larger chunk sizes. Moreover, when you move data into high-dimensional embedding space, you strip away the adjacency that exists in a contiguous block of text. You may find the precise “chunk,” but miss the logical neighbor required to make sense of it.
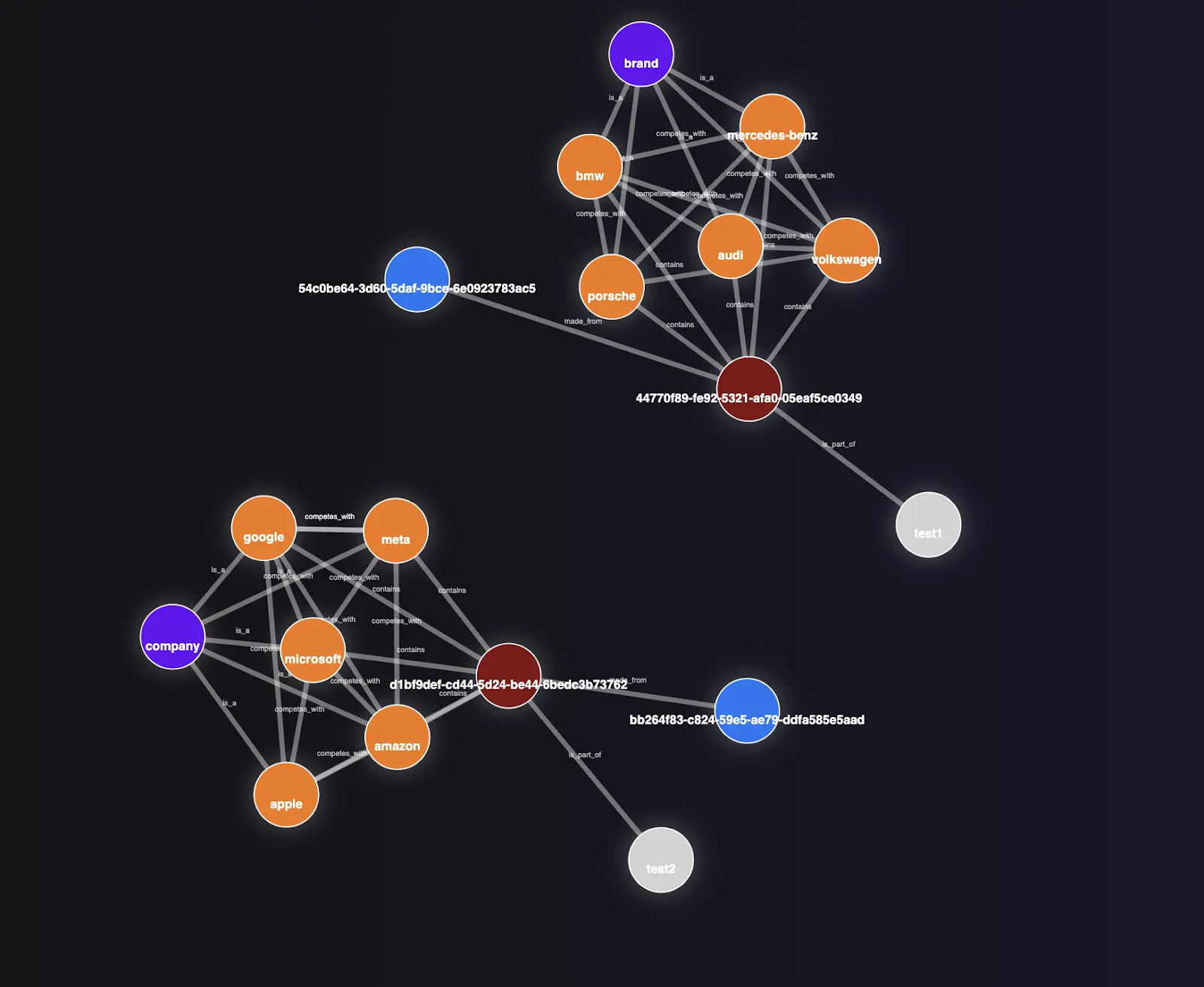
Graph-Based Memory
Graph databases (Knowledge Graphs) attempt to solve the fragmentation problem by enforcing structure. Instead of isolated chunks, data is stored as Entities (nodes) and Relationships (edges).
“Alice” [WORKS_FOR] “CorpX”.
“Jordan” [WORKS_FOR] “CorpY”.
In theory, this allows for “multi-hop reasoning” traversing from Alice, to her Employer, to her Employer’s Stock Price, in a way that Vector search cannot.
Graphs sound great in theory but are difficult in practice. You’re either trying to brute-force a relational structure of the world, or delegating labeling to an LLM, which is not reliably precise enough.
Graph memory can work well in narrow, bounded domains where entities are rigid and predictable. If you are building a bot to query an inventory system (SKUs, Prices, Warehouses) or an HR system (Employees, Departments, Managers), a graph is unbeatable. However, conversations are messy. Trying to force the complexity of the real world into a rigid graph schema results in a brittle system that breaks the moment a user says something that doesn’t fit the pre-defined ontology.
While not explicitly built for temporal purposes, some architectures claim to be able to capture date and time for temporal tracking (when memory was saved and when it occurred) through metadata stamping. In practice, this really just means stamping metadata of time with memories and doesn’t perform extremely well and bloats context.
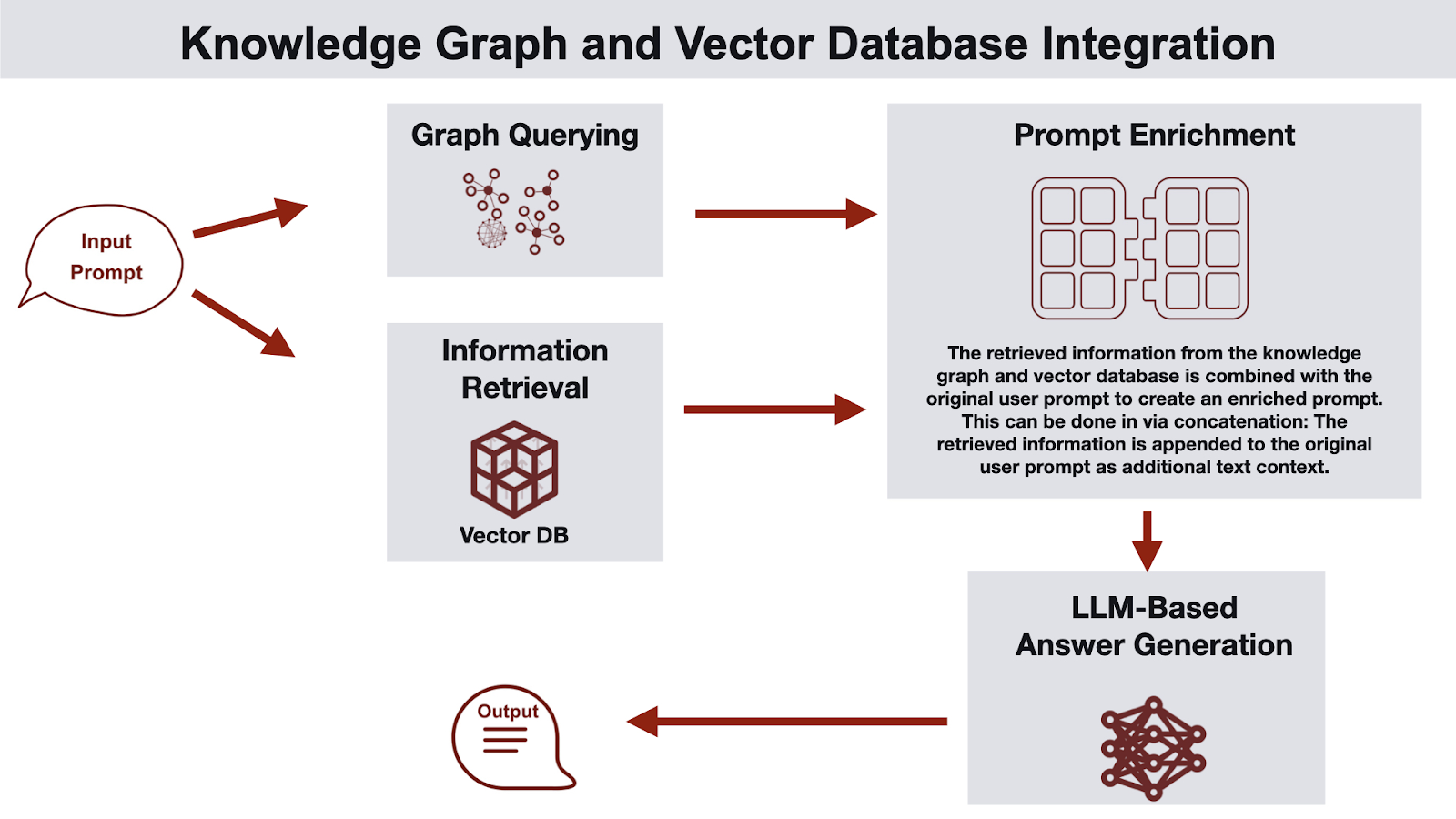
Hybrid Systems
The industry is converging on Hybrid approaches. The most promising patterns emerging in 2025 were combining Vector + Graph (GraphRAG) and Agentic RAG.
GraphRAG
While GraphRAG is often touted as the final state of AI Memory, we do not believe this will be the case. It frequently inherits the weaknesses of both systems. Adding a rigid graph to a broad, messy agentic task adds latency without improving recall. Many companies have emerged as a simple wrapper around a Graph + RAG system, but we find that they are often over-engineered and ineffective. A use case where this is valuable is when a company has a large quantity of memories where graph relationships are narrow enough to harness. In other words, when complexity is still manageable and applications have narrowly defined tasks.
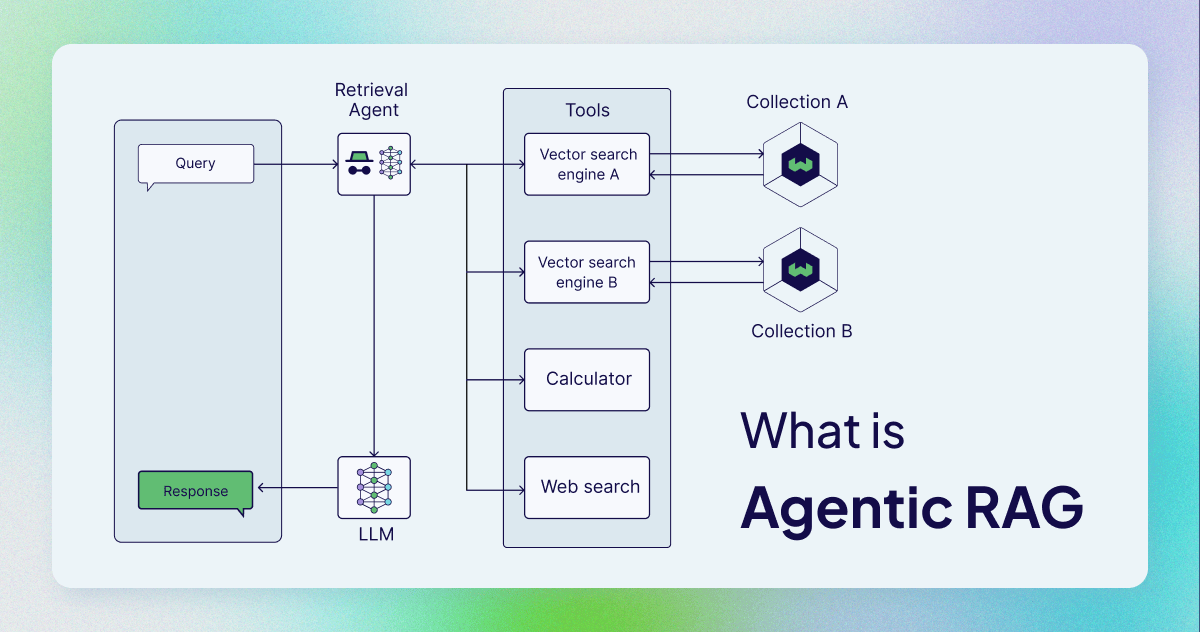
Agentic RAG
Agentic RAG is effectively running an LLM over the output of a RAG’s search. The system retrieves a broad set of potential memories using Vector search (casting a wide net), but instead of dumping them directly into the final prompt, it passes them through a cheap, fast “reasoning layer” (like Gemini Flash or Haiku). This intermediate layer acts as a sanitizer, checking if the retrieved memories are actually relevant before passing them to the main model.
This was the “sweet spot” we found when building more modern memory systems where memories per entity exceeded 50,000 tokens. Standard RAG suffers from a lack of intelligence and an abundance of context. You are often forced to decide between a targeted search that may not pull the correct memory or a broad search that returns too much context and distracts the agent. By using a cheap, fast model to distill the retrieved memories first, we mimic the human ability to glance at a notebook and decide what is relevant before starting the task. It balances the speed of vectors with the discernment of an LLM.
But even Agentic RAG, we believe, is simply a precursor to agentic memory systems.
Long-Context as “Memory”
With context windows expanding to 1M+ tokens, some argue we don’t need memory systems at all. Just dump the entire history into the prompt every time.
While effective for some one-shot tasks (e.g., “summarize this 200-page PDF”), it is economically and technically ruinous for persistent memory. Cost scales quadratically which translates to increased price per model call and Gemini models may run for 45+ seconds before returning.
Paying to re-process the same 500,000 tokens of history for every single “Hi, how are you?” message is unsustainable. Second, the “Lost in the Middle” problem is very real and proclaimed industry benchmarks on retrieving needles in haystacks are often overblown. [Arxiv] Attention is a finite resource.
One task we have found to be very useful is in running “deep memory” background jobs across all memories to create up-to-date summary for an AI. We can then store this summarization into a cache that is called at the beginning of every conversation. This provides you the processing depth of long-context without the recurring charges and 45-second bottlenecks.
Fine-tuning for Memory
While theoretically possible to fine-tune a model so that the parameters themselves hold knowledge/memory.
Fine-tuning is for teaching a model how to speak (style, format, tone), not what to know. Baking facts into model weights is the most expensive, rigid form of memory possible. If a fact changes (e.g., a user moves to a new city), you cannot simply update a database row; you must re-train the model.
This is useful, however, for procedural memory that is not straightforward how you might build memory systems for. For instance, if Google wants to make sure their AI coding agents follow general company design principles, they can bake that into their models by training on company code.
This has almost never been practical for most applications, but emerging research on the topic of continual learning and neural memory are extremely promising.
_Emerging Research: The Rise of Test-Time Training (Neural Memory)
_
While traditional fine-tuning is slow and offline, new architectures like Google’s Titans have introduced “Test-Time Training.” This allows the model to update a specific set of memory weights instantaneously as it processes new information. This effectively breaks the rule that “weights are rigid.” In this paradigm, the model does not just “read” context; it “learns” it permanently into a dedicated memory module on the fly. Still early but promising. [Titans + MIRAS]
Agentic Memory Systems
Intelligent Orchestration
Until now, memory was synonymous with a static database. Eventually, memory will flip from storage and retrieval to intelligent reconnaissance agents that reason over stored memories, find useful information and compact it to just the right size for the agent, similar to how a chief of staff might support a senior executive.
Over time, we project latency and cost of inference to approach zero, where agents will overtake RAG in efficacy. Memory will work similar to how deep research is used across the web today, yet instantaneous.
-
The Scouts: You ask a complex question. Instantly, 50 lightweight agents spawn. They don’t just “search.” First, they ask what would be helpful to know before responding, they think for themselves how deep they should search. Finally, they split up and read across your memories. One agent reads your last 100 emails, another scans your Slack, a third reads the codebase.
-
Iterative Discovery: One Scout finds a Jira ticket mentioning a “migration bug.” It doesn’t just return the text; it realizes this is important and triggers a secondary wave of agents to search specifically for “migration bug logs.”
-
The Synthesis: These Scouts feed their findings to a “Deep Reasoner” (like Gemini 2.5 Pro or OpenAI o1), which spends 45+ seconds (or minutes) thinking, filtering, and synthesizing the answer.
This is the “end game” and “meta” of memory. Deep Memory Swarms assume the question is just a starting point for an investigation. Agents will determine how deep to search as well as how and where to route to find useful context. Even this coordination process will have different orchestration architectures.
Opinionated Synthesis of Architectures
While different use cases may find each of these architectures useful for different reasons, usually there are only a couple that are useful today. Graph, RAG, hybrid, and agentic memory when effective.
If you’re building memory in 2025, start simple. Build a simple agentic memory across directories. If context bloats, add a separate vector database.
Section 3: The AI Memory Stack
For the final section of this overview, we map how memory fits into the broader AI ecosystem. Memory is not a single tool; it is a stack within a stack. Before we discuss use cases and providers of memory (Part 3), we will map out where it lives in the AI stack.
Originally, AI applications were viewed as simple “Wrappers,” thin interfaces built around a core model like GPT-4.
However, as models commoditized, the “Model Layer” shrank in importance. It has been replaced by the Context Engineering Layer. This is the new nervous system of the modern AI application, responsible for orchestration, tooling, and crucially, Memory.
The New AI Stack
-
Application Layer: The interface (Chatbot, Agent, Dashboard). The user’s touchpoint.
-
Context Engineering Layer: The “Brain.” This is where the system decides what information to fetch, which tools to call, and how to format the prompt. Memory is called here.
-
Infrastructure Layer: The “Body.” The GPUs, hosting, underlying databases, and foundational models (LLMs) that execute the compute.
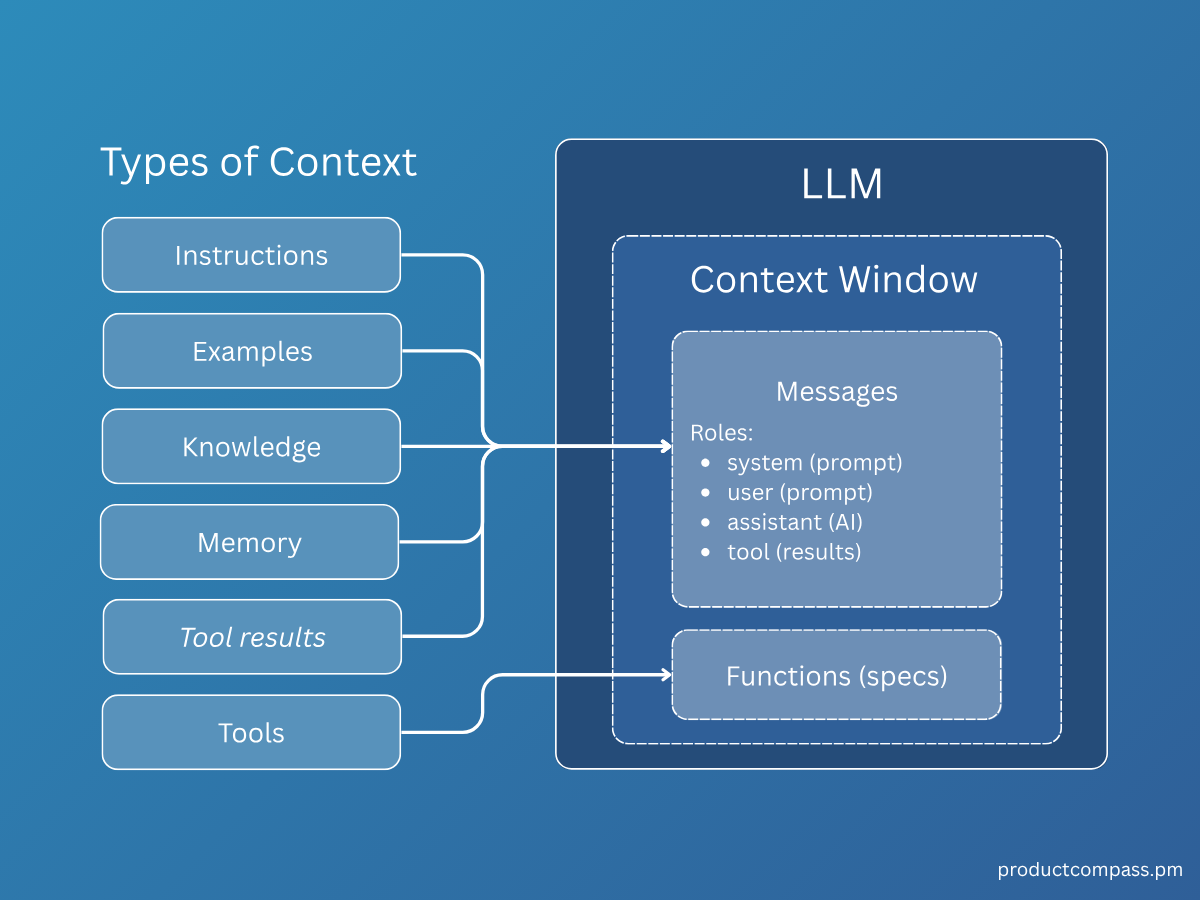
Memory
If we zoom into the “Memory” slot of the Context Engineering layer, we find a deeper sub-stack. Memory is not just a database; it is a hierarchy of needs ranging from raw storage to intelligent recall.
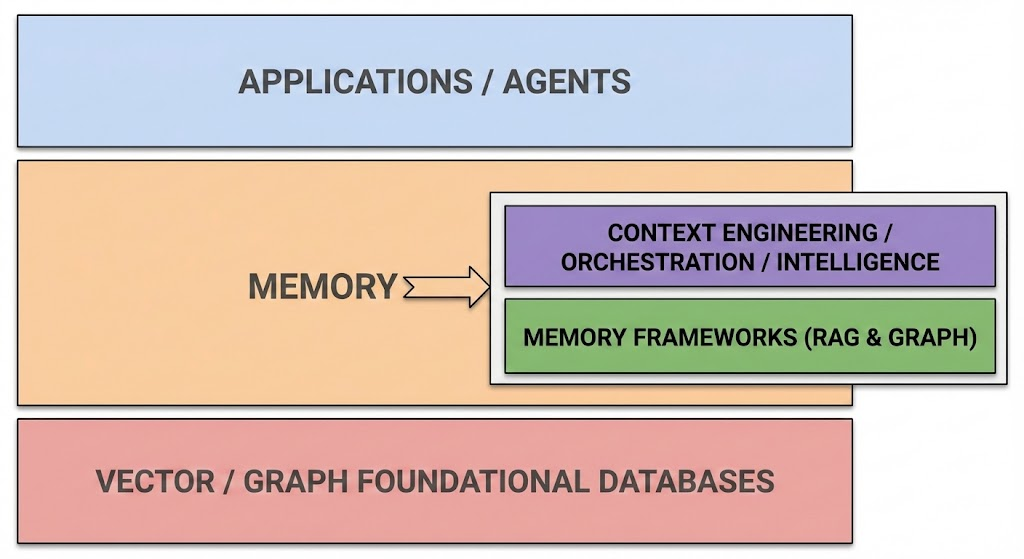
Many memory systems come out of the box with the promise of being able to set it up in “5 lines of code,” including ours. Let’s dive deeper into the different categories of memory companies. Early memory products have diverged in how abstract they are. Ideally, developers want memory to “just work” out of the box for their tasks.
Abstraction Tradeoff
There is an inherent trade-off between simplicity of use and how “opinionated” a memory product is. We can picture this as an iceberg. As you pack more complexity into products that work out of the box, you gain speed but lose control of the underlying building blocks.
In a perfect world where there is one “perfect architecture,” we would always opt for the simple-to-use memory product. But that is not the reality we live in. A coding agent requires a fundamentally different retrieval logic than a customer support bot. Because each agent has unique requirements, developers must choose where they want to sit on this stack.
Here is the memory stack, organized from the bottom (Raw Control) to the top (High Abstraction).
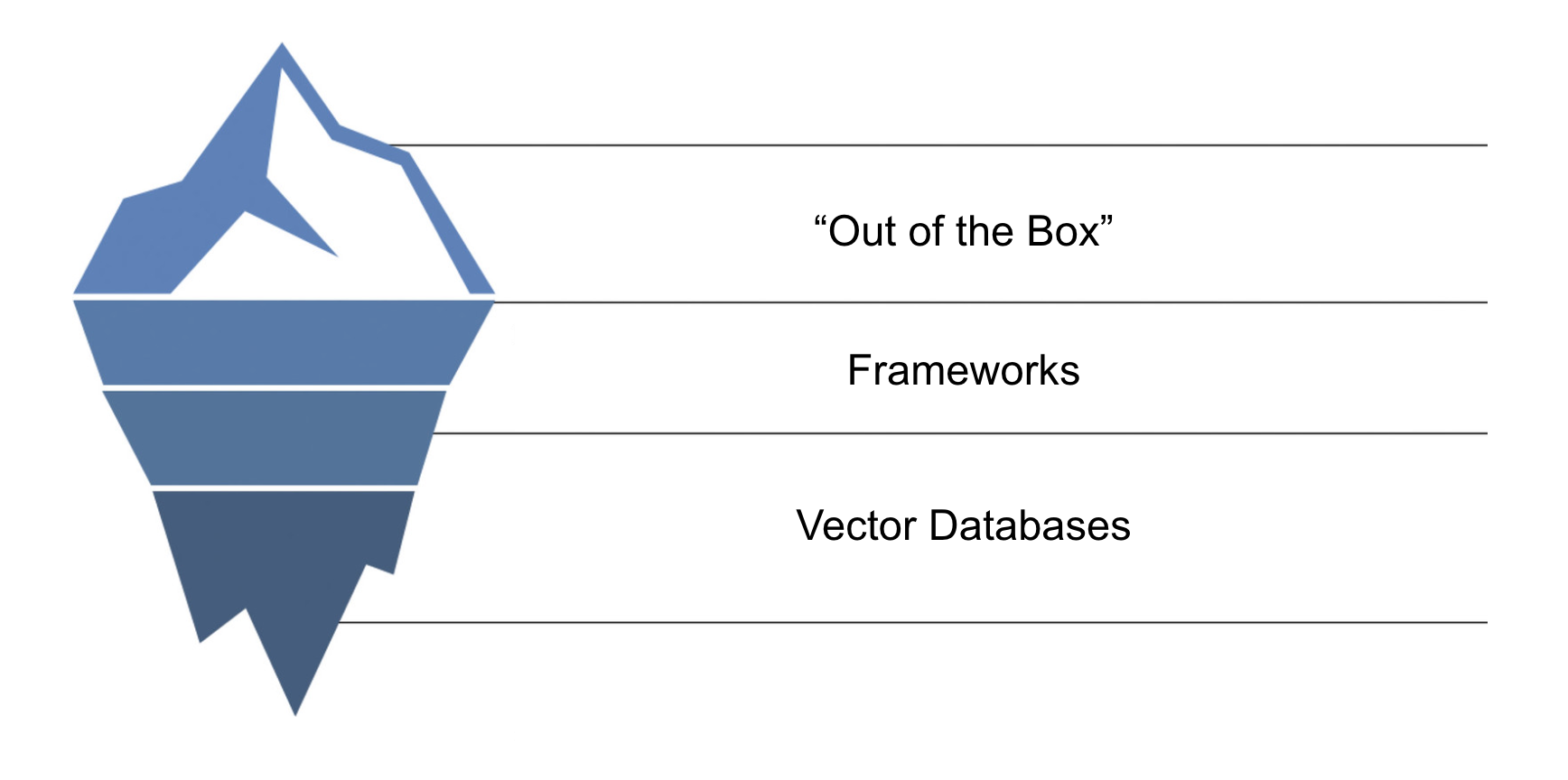
1. Low Abstraction: Foundational Databases
At the bottom of the stack lies raw storage. These are the vector and graph databases that hold the bits and bytes.
-
Pros: Total control. You define the ontology, the embedding model, and the retrieval logic perfectly for your specific use case (e.g., highly specific legal discovery vs. casual chat).
-
Cons: You must build the entire pipeline from scratch. You handle the race conditions, the scaling, and the chunking strategies.
-
Use Case: Ideal for large tech companies with sophisticated internal engineering teams or highly verticalized agents where the “standard way” of doing memory isn’t good enough.
2. Medium Abstraction: Memory Frameworks
Sitting in the middle is a layer of frameworks that abstract away de-duplication, timestamping, managing metadata, and standard functions like add_memory or search_memory. Some are open-source so developers and companies retain some control over tuning the product for their use.
-
Pros: You don’t need to reinvent memory from scratch while maintaining relative control. You can tweak the chunking algorithm or swap the underlying database if needed.
-
Cons: It is not “plug and play.” It still requires a developer to integrate these blocks into their product and make architectural decisions.
-
Use Case: The sweet spot for most serious developers who need velocity but cannot afford to be locked into a black box.
3. High Abstraction: Developer Tools & “Batteries Included”
At the top of the stack are managed services and developer tools. These solutions promise “Memory in 5 lines of code.” Sometimes this is a complex orchestration engine; other times it is simply a hosted tool that abstracts the different tools from the frameworks.
-
Pros: It “just works.” The provider handles the embedding models, the infrastructure, and the logic. You simply make an API call.
-
Cons: You lose control. If the provider’s chunking strategy cuts off critical context, or if their retrieval logic prioritizes the wrong memories, you often cannot fix it. You are locked into their “opinion” of how memory should work. May not allow self-hosting.
-
Use Case: Perfect for MVPs, simple chatbots, or applications where memory is a feature, not the core product differentiator. If you can find an abstract, opinionated memory solution that is perfect for your use case, this is ideal.
Conclusion
Memory is not RAG. It is a complex pipeline filtering, storing, and reorganizing experiences for future recall. As memory systems become more sophisticated, we are forced to make very real design decisions across different architectures.
For developers, consider your downstream use case before implementing any product you find online. Start simple and experiment.
In Part 3, we will explore more tangible use cases of memory and evaluate the AI Memory market as a whole. With such a quickly developing space, we are left questioning where exactly value will accrue.
—
Part 2 of a 4 part series on AI memory.
If you are interested in implementing memory systems, reach out to Jean.
— jonathan@jeanmemory.com