AI Memory: Future Outlook
A comprehensive review (part 4/4)
Introduction
We have now reviewed the history of how AI Memory formed (part 1), a technical overview for developers building memory systems (part 2), and a review of the current state of the market (part 3). Or see the full report here.
We will now synthesize all of this information into a future outlook. We will briefly review each section we have written and extract core themes, before weaving them into 4 forward-looking theses.
Mainly, history will be rewritten. We started this series by asserting that “in order to understand memory, we must first forget it.”
RAG was a band-aid and will be replaced with agentic, active memory over time. Value will flow towards platforms and vertical, high-value memory products. The space is growing unpredictably fast with many emerging use cases and opportunities that we expect to branch out in many directions.
Part 1: Pre-History
In our first section, we looked into the past to understand how we arrived at today’s idea of AI memory. Mostly, AI Memory was born out of the simple problem that LLMs are “stateless” and do not remember. The first simple fix was to just throw the entire conversation into every new prompt, forming a “short-term memory” of what has occurred in the current chat.
The first appearance of a long-term memory store came in the form of RAG and web search, where one could access context outside of the chat window. These were still primitive at the time.
RAG was retrofitted for memory, but it was clear this was only because function calling was unreliable and expensive. Structured output and Model Context Protocol (MCP) had not arrived yet. Over time, prompt engineering evolved into context engineering. Memory was now a core part of every AI Agent, yet we were still using unintelligent memory systems of the past.
Part 2: Technical Foundations
In the second section, we evaluated memory from first principles. What is memory and what is its purpose? We posit that memory is not destined to be passive (as it currently is), it is ideally active and propose the E → S → R pipeline, where memory is an intelligent process of its own.
We claim that we wouldn’t segment memories at all in a perfect world, and that partitioning was the “original sin” of AI Memory. This ties into the narrative that RAG was retrofitted for memory. It was the obvious solution. But as we approach a new age, memory should be agentic by default.
We reviewed each architecture for memory and their strengths / weaknesses, including anecdotes from building these systems. Lastly, we propose the idea of the memory stack, where foundational databases lie at the bottom and are abstracted away into more opinionated memory products.
Part 3: Market Dynamics
In the third section, we take a step away from the code to touch grass and look at how people are actually using memory today. We ask where the value is accruing in the market. We acknowledge the present use cases, how developers decide whether to build or buy, and the gaps in the market.
It was clear in section 2 that different architectures have different strengths. In section 3, it also became clear that different use cases required drastically different architectures. Logically, this leads us to reject any “one-size-fits-all” solution, which opens the door to rich market fragmentation and competition.
We conclude that foundational storage has been commoditized. Value is accruing from AI applications downwards. So in order to understand where value accrues, we must look to developer activity.
The logical memory choice for developers is to inherit the memory of the LLM provider like OpenAI or Anthropic, especially when memory is not core to the value of the application. However, these general solutions are designed to be general and do not perform well for every different use case.
In the event a company has a unique use case where memory is core, they may decide to build their own memory, build on top of memory frameworks, or purchase a vertical memory solution. The largest question we have today is where, among these three choices, will developers lean the hardest? We attempt to answer this question in thesis 2 of this write-up.
Thesis 1: The Future of Memory is Agentic
Since segmentation is the necessary evil / “original sin” of memory and RAG was retrofitted for this use case, we posit that RAG will be demoted in the memory stack. For low context applications, we will start by building agentic memory. We will add memory blocks and RAG only as context size increases above manageable thresholds. Anthropic and Letta’s philosophical design choices a glimpse into the future of AI Memory.
Many enterprises may still have narrowly defined tasks. Graph and GraphRAG will still perform well in domains where ontologies can be effectively harnessed.
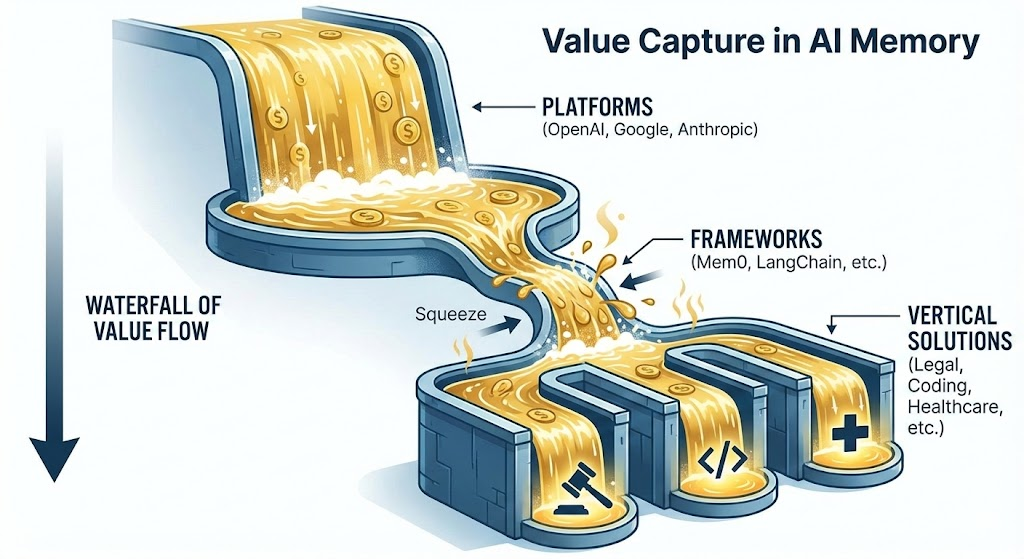
Thesis 2: Waterfall of Value
We anticipate that the value accruing to memory will flow to those with obvious distribution advantages and only flow downwards to those who solve high-value problems that incumbents cannot.
Platforms
Platforms such as OpenAI, Anthropic, and Gemini have strong distribution advantages, and will capture the majority of simple value. We expect that general platforms will be the rising tide whose memory will work for most general cases. Their generality, however, will leave their products unsuited for use cases that require specific memory solutions. After building our own products with memory, we saw the limitations of the basic memory solutions.
Memory Frameworks (Squeeze)
Memory frameworks have won developer mindshare first, abstracting some of the more high-level decisions in building memory systems, but they are getting squeezed by applications who choose to build themselves and narrower, high-value vertical memory solutions that either build on top of their open-sourced components or build separately.
Mem0 was the breakaway leader in this category, but long-term profitability concerns remain. They have also built a product that assumes RAG becomes the core primitive, rather than an agentic memory. As we have reviewed extensively, RAG isn’t going anywhere, but it should be re-evaluated as the backbone of memory systems.
Vertical Memory
For now, vertical memory as a category is nascent but growing fast. Over time, we expect the vertical category to expand with demand and increasingly divergent memory requirements. Many vertical solutions may build on Mem0 and other open-sourced frameworks and take their lunch.
Many vertical memory solutions will naturally slot into various domains (legal, finance, healthcare) as well as different use cases (enterprise agents, personalization, voice agents).
Thesis 3: Memory is Still Early
Memory is not just recall. After you have built large memory banks, we can then ask important questions about how we can use those stores. We are building the next generation of persistent, personalized products, long-running intelligent agents, and more. Increasing variety and sophistication of AI Applications and Agents lead to an increase in demand for new memory products.
Indeed, the introduction of new memory products also paves the way for new applications. New interfaces will call you by name and generate UI on demand for your unique personality and interests at that moment.
Thesis 4: The Prize is Cross-Application Context
We started down this road by recognizing that the biggest prize in the age of AI was going to be who would own the user context layer. Our context is fragmented across siloed applications, each seeing only a narrow slice of our holistic identities. This has been a tough nut. Many companies have already lived and died attempting to crack it.
Memory is the logical form factor for this cross-application context. Judging from the actions of OpenAI, this is likely where they see their largest opportunity and are gearing up to capture it. Users want this in principle but are also privacy conscious. As memory solutions fragment increasingly, the likelihood that OpenAI becomes the ubiquitous winner falls.
The winner may not be a platform at all. It may be a neutral identity layer that connects fragmented memory systems, letting users port their context across applications without any single provider owning them.
Conclusion
While AI Memory as an industry is beginning to take shape, it is young. There is no telling how the future can unfold. But we have made some projections after evaluating the space holistically from the ground up.
-
Memory will become increasingly agentic over time.
-
The majority of value in memory will accrue to the big platforms and high-value opinionated memory products.
-
We are seeing an explosion of use cases on top of the foundation of memory. We will continue to see new use cases requiring new memory solutions.
-
Whoever wins cross-application context / user identity will become one of the most valuable companies in the world. The walled gardens of the past built empires around user data. User context is much more valuable.
Thanks for sticking with us for our comprehensive review of AI Memory. As always, if you have any questions or are interested in building AI Memory, reach out to Jean.
—
Part 4 of a 4 part series on AI memory.
If you are interested in implementing memory systems, reach out to Jean.
— jonathan@jeanmemory.com